Ian is an Eclipse committer and EclipseSource Distinguished Engineer with a passion for developer productivity.
He leads the J2V8 project and has served on several …
Cloud native, highly available, web-scale, coordinated containerized applications! Wow, that’s a mouthful, but what does it mean?
Over the past six years, many large companies have started telling the world how they architect their systems to scale. From the now famous Netflix Global Cloud Architecture to Google’s Borg system, many of these companies have been solving the same problem using similar patterns. The systems are designed as a (large) set of small, stateless services, which run in containers on cheap hardware, coordinated by one (or many) cluster managers. The services are replicated many times, so if one fails, traffic is redirected to another node. Pieces can be turned off, updated or rolled back, all without any downtime. For truly global companies, the software can run on different datacenters around the world, and users will access the nodes closest to them.
This architecture isn’t new, and many of you have probably had to explain this design during a recent job interview. But what is new, is how wide-spread this architecture has become. This design is no longer just for services with a few billion page hits per day. Over the past 18-24 months, it seems every company has begun to hire DevOps professionals with experience in Cloud Native Computing.

Google created the Cloud Native Computing Foundation to house Kubernetes, the leading orchestrator for containerized applications; and an entire eco-system of products and services has flourished.
 Companies both small and large are using the technologies for a whole host of reasons:
Companies both small and large are using the technologies for a whole host of reasons:
As demand for these expertise grows, one question that has always interested me is: how can we better teach these concepts and enable others to learn? Kubernetes has a single node distribution called Minikube, which is an excellent resource for learning. Kelsey Hightower has put together a fantastic tutorial, Kubernetes the Hard Way, which steps you through the entire process of rolling out Kubernetes on the Google Cloud Engine.
Both of these are excellent resources, and I highly recommend them. But a single node cluster doesn’t have the same characteristics as a multi-node setup, and the Google Cloud Engine feels a bit abstract. What if you want something you can touch? Something you can take apart, reboot and re-assemble?
To help explain the details of Kubernetes, EclipseSource has purchased a physical Kube Cube – A PicoCluster. The cluster consists of 10 Rock64 boards, each with 4Gb of RAM. Each board is connected to a power supply and network adapter. The entire cluster can be accessed through the master node using a mouse/keyboard/monitor, or over the network via ssh. The cluster is housed in a slick, solid plastic case. The box also came with 10 MicroSD cards, configured with Ubuntu and Kubelet.

Each card is configured with a Static IP Address from 10.1.10.240 - 10.1.10.249. I set my router to use the same subnet and booted the cluster.
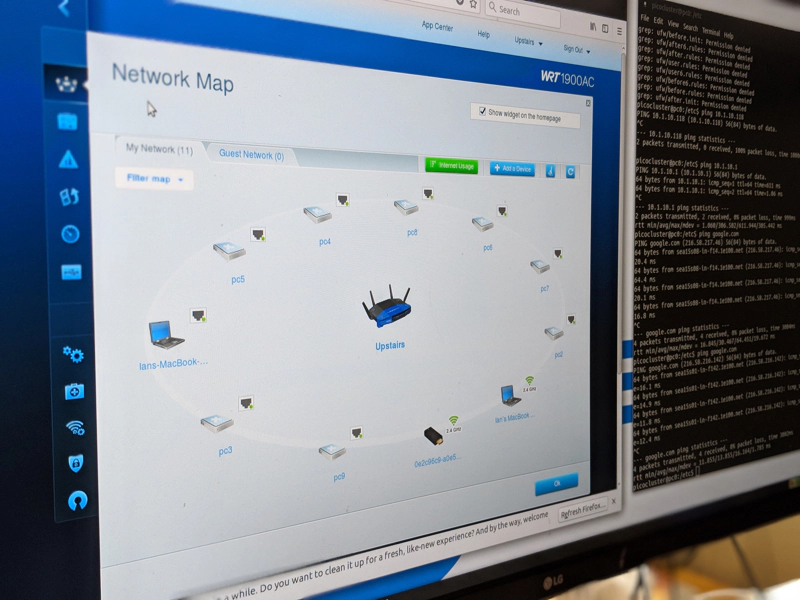
I configured the kubectl on my development machine to talk to the PicoCluster (I will write a short post on how I did that), and from there I was able to manage my custom Kubernetes cluster.
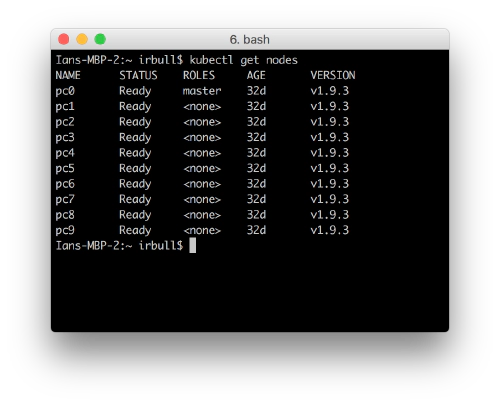 Over the next few weeks and months, I’m going to document my experiences with Distributed Computing, Kubernetes, the PicoCluster and in particular how we can use this setup for Big Data analysis with Spark. If you’re interested in following along, follow me on Twitter.
Over the next few weeks and months, I’m going to document my experiences with Distributed Computing, Kubernetes, the PicoCluster and in particular how we can use this setup for Big Data analysis with Spark. If you’re interested in following along, follow me on Twitter.

Ian is an Eclipse committer and EclipseSource Distinguished Engineer with a passion for developer productivity.
He leads the J2V8 project and has served on several …